지난 게시글에서는 새로운 정부가 들어섬에 따라 추진하고자 하는 AI 정책들을 알아보고 정책 안에서 어떠한 가능성에 투자하여야 하는지에 대해 살펴보았다. 결론부터 이야기하자면 AI 시장의 규모는 세부적인 분야가 어느 분야던지 간에 상관없이 연평균 10% 이상의 성장률을 갖고 성장할 것으로 예상되는 만큼 모든 산업 분야가 급속도로 성장할 것이며, 결국에는 ✅ 평균적인 성장률보다 높은 폭으로 성장하는 분야에 집중해야 한다. 그 안에서도 AI 기술을 활용하여 눈에 띄는 성장률을 보이는 기업에 대해 알아두어야 하는데, 이번에 살펴볼 주제는 LLM이다.
LLM(Large Language Model)은 거대언어모델을 뜻하며, 이는 AI를 활용하는 모든 분야에서 활용되며 AI의 기반을 구성하는 개념으로 조금 자세하게 이해한다면 생활과 가장 밀접하게 연관되어 있는 Chat GPT와 같은 AI 기술을 사용할 때 그 1️⃣ AI를 사용하는 가장 효율적인 방법, 그리고 향후에 LLM을 기반으로 생겨나는 여러 가지2️⃣ 사업들의 성장 가능성을 예측하고 이해하는 데에도 도움이 될 것이다.
LLM(Large Language Model), 거대언어모델이란 무엇인가 ?
거대언어모델은 그냥 Large Language Model이라는 용어를 번역한 것에 지나지 않으니 그냥 앞으로는 LLM이라 부르기로 정하고 넘어가도록 하자. LLM의 정의를 내려보자면 '텍스트 데이터를 학습시켜 사람처럼 말하고 쓸 수 있도록 만든 인공지능 모델'이다. 조금 간단하게 생각해보자면, 전통적인 방식에서의 프로그래밍은 사람이 학습한 컴퓨터의 언어(C++, Python)를 사용하여 컴퓨터에게 컴퓨터의 언어로 '어떻게 작동하여야 하는지'를 지정해주는 방식이었다. 하지만 LLM은 컴퓨터가 사람의 언어를 학습하도록 해서 그를 바탕으로 우리가 이야기하는 문장의 맥락을 이해하도록 학습시킨 결과물이다. 즉, 컴퓨터가 학습한 텍스트 데이터를 토대로 우리가 전하는 문장이 어떤 것을 의미하는지 이해하고 그에 따른 적절한 답변을 내어주는 의사소통을 할 수 있게끔 만든 것이다.
그렇다면 LLM은 무엇이 있을까 ? 우리 주변에서 가장 흔히 접할 수 있는 LLM으로는 Open AI 사에서 내놓은 Chat GPT가 있다. 이 Chat GPT는 수많은 언어로 이루어진 여러 가지 문서들을 토대로 언어를 학습하고 학습한 언어로 여러 가지 데이터를 수집하고 수집한 데이터를 통해 'A란 무엇인가 ?'에 대해 설명할 수 있는 지식을 갖추게 된 것이다. LLM을 어렵게 생각하면 어려운 거겠지만, 간단하게 생각하면 영어를 한국어로 번역하는 것도 텍스트 데이터를 학습하여 우리가 필요한 정보를 제공해준 다는 점에서 LLM에 해당한다고 볼 수 있다. (물론 옛날의 번역기와는 다소 다르다.) 그렇다면 LLM은 텍스트 데이터를 어떤 방식으로 학습할까 ?
예를 들어, 'Homepage'라는 영어 단어를 제시해줬을 때 한국에서는 이 단어를 뭐라고 하는지에 대해 여러 가지 텍스트 데이터를 찾아가면서 학습하게 된다. 만약에 학습시키고자 하는 10개의 데이터 중 'Homepage'를 '홈페이지'라고 지칭하는 데이터가 9개, '사이트'라고 지칭하는 데이터가 1개가 있다고 하면 이제 'Homepage'라는 단어는 90%의 확률로 '홈페이지'라고 지칭한다는 내용을 학습하게 되는 것이다. 만약 10개의 데이터가 아닌 100개의 데이터를 학습시킨다면 어떨까 ? 100개의 데이터 중에서도 마찬가지로 'Homepage'라는 영단어를 '홈페이지'라고 지칭하는 데이터가 86개, '사이트'라고 지칭하는 데이터가 12개, '홈피'라고 지칭하는 데이터가 2개가 있다고 한다면 'Homepage'라는 단어는 86%의 확률로 '홈페이지'라고 지칭한다는 정보를 학습하게 되는 것이다. 만약에 이 과정을 계속해서 반복해나간다면 아래와 같은 결과값이 프로그램 내에 탑재되는 것이다.
더 나아가 '홈페이지'라는 단어를 가지고 어떠한 문장을 만들고자 한다고 가정해보자. 이 단어 뒤에 따라붙어야 하는 조사는 무엇일까 ? '은', '는', '이', '가' 등과 같은 수많은 조사 중에서 '홈페이지'라는 단어 뒤에 따라 붙어야 하는 조사를 학습해야 한다. 이 때도 위에서 학습한 방식과 똑같은 방식으로 '홈페이지'라는 단어를 통해 '는', '가'라는 조사가 몇 %의 확률로 따라붙을 수 있음을 학습하게 되고, 결국 컴퓨터는 학습된 데이터를 바탕으로 '홈페이지는 영어로 Homepage라고 합니다.'라는 문장을 구사할 수 있게 된다. 여기서 한 발 더 나아가, 사용자가 이 프로그램을 사용하면서 사용자가 지시하는 작업을 다시 분석하고 이해하며 수정해주는 과정을 통해 프로그램은 〔강화 학습〕을 하게 되고 그 결과로 더 매끄럽고 자연스러운 결과값을 제시할 수 있게 된다.
이러한 맥락에서 LLM은 1️⃣ 텍스트 데이터가 많이 그리고 잘 학습된 프로그램일수록, 2️⃣ 사용자가 작성한 문장의 의도를 더 정확하게 파악할수록, 3️⃣ 자신이 처리하여야 하는 업무가 무엇인지 그 범위를 정확하게 파악할수록, 그리고 4️⃣ 처리하여야 하는 데이터를 얼마나 잘 찾아서 사용자가 필요한 형식과 언어에 맞게 정제하는지 등과 같은 여러 가지 기준에 따라 LLM의 성능이 평가된다.
그래서 LLM 가지고 뭘 할 수 있는데 ?
앞서 살펴봤듯 LLM을 정리하자면 컴퓨터에게 사용자의 언어를 학습시킨 후 학습된 데이터를 토대로 사용자의 문장을 이해하고 정확하게 파악하도록 함으로써 사용자의 요청을 이해하는 것이다. 이제, 컴퓨터가 내 요구가 무엇인지 이해하게 되었다면 나와 컴퓨터는 상호작용을 통해 무엇을 만들어낼 수 있을까 ? 사실 범주를 나누어보자면 AI를 활용하여 만들어낼 수 있는 범위는 무궁무진하다. 알고 있을지도 모르고 전혀 체감하지 못할 수도 있겠지만, AI는 이미 우리의 실생활 속에 깊에 자리잡고 있다.
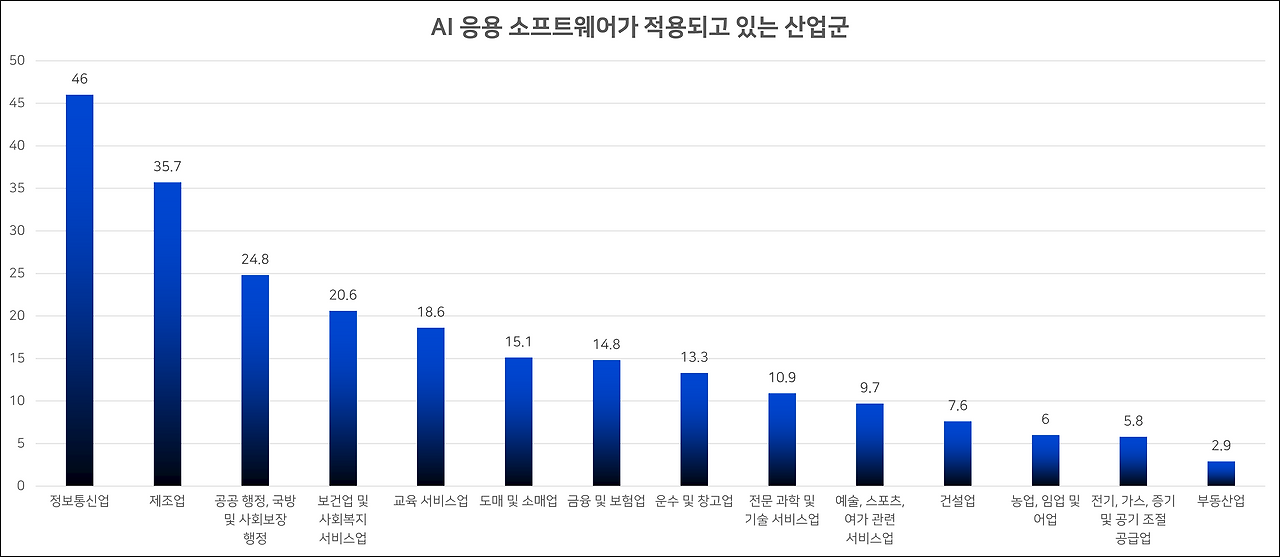
출처: 과학기술정보통신부, 2024 인공지능산업 실태조사. p.30.
가장 먼저 고객 서비스 분야에서 제공하는 1️⃣ 챗봇 서비스나 콜센터 자동화 등을 생각해보자. 먼저 카카오엔터프라이즈(카카오)의 '카카오 i 커넥트 톡'이라는 챗봇 AI를 신용보증기금에서 '신보톡톡'이라는 챗봇 서비스로 활용하고 있으며, LG CNS에서는 'AI Service for X'라는 이름 하에 상품을 주문하거나 티켓 예매, 마케팅, 24시간 상시 응대 챗봇 상담원 등 수많은 분야에서 챗봇을 통해 사람이 해야 하는 일을 대체하고 있다. 기존에 상담원이 직접 눈으로 확인하고 손으로 타이핑하거나 귀로 듣고 입으로 말하며 처리해야 했던 업무들을 챗봇이 대신 처리해주고 있는 것이다. NAVER의 경우에도 'CLOVA X'를 기반으로 통계청과 서울특별시의 서울데이터허브에 AI 챗봇 서비스를 제공하고 있으며, KMI 의학연구소에도 asKMI 챗봇을 제공하고 있다.
다만 챗봇 서비스와 관련하여, 실제로 카카오톡 채팅 상담을 이용해본 경험이 있을 것이다. 실제로 거의 모든 기업체들이 카카오톡에 공식 채널을 만들어서 해당 카카오톡 채널을 통해 상담을 진행하거나 문의사항을 주고 받을 수 있도록 하고 있다는 점을 생각해보면, 카카오톡은 LLM의 학습을 위한 수많은 데이터를 가지고 있다는 점에서 가장 많은 데이터 학습을 보유하고 있는 기반이 마련되어 있다고 볼 수 있다. 또한 서울특별시의 경우 120 다산콜센터를 통해 접수된 여러 가지 민원 사례들을 '서울톡'이라는 카카오톡 챗봇 서비스를 구현함으로써 민원 처리 속도가 높아졌는데, 이 과정에서 수많은 데이터를 학습하고 활용할 수 있다는 점에서 만약 카카오가 카카오톡에 있는 다른 기업들의 상담 채널에 자사의 LLM을 활용한 챗봇 서비스를 제공하게 된다면, 가장 많은 데이터를 학습할 수 있게 되는 가능성을 가지고 있기도 하다. 물론, 네이버의 경우에도 수많은 언론사들이 엄청난 양의 뉴스를 업로드해주는 네이버 뉴스라는 플랫폼이 있기 때문에 이를 통해 수많은 텍스트 데이터들을 학습하고 기능을 향상시킬 수 있다는 장점이 있다. 실제로 네이버 뉴스에 들어가서 보면 본문 요약봇이라는 기능이 있는데, 그 버튼을 눌러보면 전체 뉴스 기사를 간단하게 요약해서 보여주는 기능이 있기도 하다.
LLM이 가장 잘 활용될 수 있는 곳이 어디일까 ? LLM은 텍스트 데이터를 학습하고 그를 바탕으로 새로운 결과물을 만들어내는 만큼, 수많은 텍스트를 분석해야 하는 곳에서의 효과가 장 클 것이다. 조금만 생각해보면 어렵지 않게 떠올릴 수 있는데, 텍스트의 양이 많은 분야로는 2️⃣ 법률 분야와 교육 분야를 손에 꼽을 수 있다. 먼저 법률 분야의 경우에는 기본의 변호사들이 (물론 기본적인 초안은 복붙한다 하더라도) 수기로 작성해야 하는 문서들이 많았고 그 문서를 재차 읽어보고 다시 검토하며 문장을 다듬는 시간에 많은 시간을 할애하게 된다. 실제로 준비서면과 같은 서류를 작성할 때 그 기반이 되는 판례들을 계속해서 검색하고 찾아보고 논점을 정리하며 작성해야 하는데, AI에게 수많은 판례를 학습시킨 후 AI가 그때마다 적절한 근거가 될 수 있는 판례를 찾고 그 요지를 정리하여 서류를 작성해줄 수 있게 된다. 물론 AI가 만들어낸 서류를 변호사가 다시 한 번 확인하고 검토하는 과정을 반드시 거쳐야만 하겠지만, AI의 궁극적인 목표는 생산성 증대와 편리함에 있다는 점을 고려하면 그것만으로도 충분한 이익을 가져다줄 수 있을 것이다. 실제로 로앤컴퍼니에서는 GPT-4를 기반으로 만든 로톡(빅케이스 GPT)를 주력으로 서비스하고 있으며, 업스테이지 사의 자체 LLM인 솔라를 기반으로 만든 솔라 리걸(Solar Legal), 여러 가지 LLM과 자체 아키텍처를 결합해서 만든 슈퍼로이어도 서비스하고 있다. 교육 분야 역시 현재 국내외 대부분이 Open AI 사의 Chat GPT를 중심으로 문제를 제시하고 학생의 수준에 맞는 해설을 제공해주거나 다른 질문에 대한 답을 제시해주는 등의 기능이 주를 이루고 있다. 다만 NAVER는 HyperCLOVA X를 활용하여 경상북도교육청에 AI 챗봇 서비스를 제공하고 있으며, 업스테이지는 Solar LLM을 활용하여 대학 및 교육기관의 프로젝트 등에서 LLM 연구와 실습을 목적으로 LLM 서비스를 제공하고 있다. 교육 분야의 경우에도 법률 분야와 마찬가지로 수많은 논문 데이터나 문제들을 학습하고 그를 연구자 또는 학생의 수준에 맞추어 설명해주는 기능도 존재하겠지만, 더 나아가서는 향후에 연구할 필요성이 있는 주제를 제시하거나 학생에게 필요한 학습 목표를 제시하고 그 길로 유도하는 등의 기능도 만들어질 수 있을 것이다.
다음으로 화제가 되는 것은 3️⃣ 프로그래밍이다. 실제로 Chat GPT에 들어가서 '어떠한 기능을 만들려고 하는데, 어떤 언어로 프로그래밍해줘.'라고 요청하면 곧바로 작동할 수 있는 코드를 생성해준다. 하지만 Chat GPT는 그 기본값이 대화형 및 생성형 AI인 만큼, Open AI에서는 코덱스(Codex)라는 AI 코딩 도구를 공개하였고 Anthropic도 이에 질세라 클로드 코드(Claude Code)라는 AI 코딩 도구를 공개했다. Google도 이에 질세라 Gemini CLI를 통해 '웹사이트 만들어줘'라고 요청하면 곧바로 HTML 코드를 만들어주는 등의 기능을 사용할 수 있는 AI 에이전트를 출시할 예정이다. 물론 코딩 관련해서는 사용자가 원하는 부분까지 디테일하게 캐치해서 만들어주진 못하지만, 어떤 부분에 오류가 발생할 수 있으니 그 부분을 고려하여 이렇게 만들어달라고 하면 그 내용을 고려하여 새로운 코드를 만들어주는 수준까지는 올라왔다. 또한 NAVER 역시 CLOVA Studio를 통해 하이퍼 클로바 X를 활용한 코딩이 가능하긴 하나, 아직 계속해서 개선해나가야 하는 수준이며 해외의 LLM들에 비하면 그 기능이 많이 떨어지는 것이 현실이다.
여기까지의 내용을 간단하게나마 잘 읽었다면 기업들이 LLM을 만듦으로써 추구하고자 하는 가치가 무엇인지 어렵지 않게 알 수 있다. 즉, 컴퓨터에게 사람의 언어를 학습하도록 함으로써 사용자로 하여금 어려운 프로그래밍 언어를 공부하거나 시간을 들여 자료를 찾아보는 등 '컴퓨터가 해준다면 얼마 걸리지 않을 작업'들을 사용자로 하여금 어렵지 않게 대체함으로써 ✅ 효율성을 극대화하는 것이다.
World Best LLM, WBL 이란 무엇인가 ? : 독자 AI 파운데이션 모델
WBL(World Best LLM)이란 '국가대표 초거대 AI 모델'을 육성하기 위한 사업으로, 과학기술정보통신부의 주도 하에 1️⃣ GPU 등의 인프라 확충, 2️⃣ AI 스타트업 및 인재 육성, 3️⃣ 공공데이터 개방이라는 3개의 화살을 가지고 세계 최고 수준의 LLM을 개발하는 프로젝트이다. 이 World Best LLM은 프로젝트 시작 시점에 지어진 가칭인데, 이는 2025. 6. 20. 기준으로 〔독자 AI 파운데이션 모델〕이라는 이름으로 확정되었다.
이 LLM을 국가 차원에서 개발하고자 하는 이유는 무엇일까 ? 궁극적인 목표라면 (소버린 AI라는 측면에서) 당연히 ✅ '민간 차원에서의 다양한 AI 서비스 출시 및 경제사회 전반의 AI 전환 가속화'일 것이다. 하지만 이 목적을 어떻게 이뤄내겠다는 것일까 ? 일단 이 프로젝트를 통해 정부가 달성하고자 하는 과업은 최신(6개월 이내 출시된) 글로벌 AI 모델 대비 95% 이상의 성능을 갖고 있는 LLM 모델을 개발하고, 이를 오픈 소스로 여러 기업에 제공하게 되면 큰 개발비를 들이지 않고 꽤 좋은 성능의 LLM을 사용할 수 있게 된 기업들이 다양한 AI 서비스를 만들고 소비자에게 제공할 수 있게 되며 더 나아가 B2B 측면에서도 AI 서비스가 많이 공급될 것이며 궁극적으로는 👉 경제 전반의 AI 전환을 이루어내는 것이다.
(인프라 확충) '26년 상반기까지 민간의 GPU를 임차 지원하고, 이후부터는 정부 차원에서 GPU를 구매하여 지원함
(인재 육성) AI 인재를 키우기 위한 것으로, 이 프로젝트에는 대학생과 대학원생의 참여를 필수로 함
(공공데이터 개방) 의료 분야 등 공공기관에서 보유한 고품질 데이터를 개방하여 산업별 특화 AI 서비스 탄생 유도
이 프로젝트는〔모두의 AI를 개발하겠다〕는 이재명 정부의 공약과도 일맥상통하는 것으로, 일단 이 프로젝트에 참여하는 정예팀은 ① 국민의 AI 접근성을 증진시키고 ② 공공·경제·사회 전반에 걸쳐 AI 전환을 통한 국내 기여 계획도를 제시하여야 한다. 처음에는 최대 5개의 팀을 선발한 후, 단계별 평가를 통해 LLM의 성능을 경쟁시키고 점차 지원하는 팀을 줄여나가는 방식으로 진행된다. 이후 이 프로젝트는 오픈 소스를 지향하므로 최후에 살아남은 독자 AI 파운데이션 모델은 상업적으로 이용할 수 있도록 공개될 것이며, 이 모델의 안전성을 검증한 후 이 모델에 'K-AI 모델'이라는 명칭과 참여한 기업에게 'K-AI 기업'이라는 명칭을 사용할 수 있도록 하여 해당 기업과 한국의 AI 기술력에 대한 공신력을 강화하고 글로벌 시장에의 진출을 가속화할 예정이다.
728x90
그래서 어떤 LLM이 제일 좋은데 ?
먼저 LLM의 종류를 살펴보자면 가장 흔히 알고 있는 Chat GPT(Open AI), Gemini(Google)나 Claude(Anthropic), LLaMA(Meta), Grok(xAI), 그리고 얼마 전 미국 증시의 급락을 야기했던 무역전쟁과 함께 엔비디아의 GPU로부터 발생하는 높은 마진율 독점이 끝난 거 아니냐는 이슈를 만들어냈던 DeepSeek(DeepSeek)등이 있다. 흔하게 사용하는 Chat GPT나 Gemini 모두 LLM이라는 거대언어모델을 기반으로 언어를 학습하고 문장을 구현하며 사용자와 상호작용한다. 국내의 경우에는 HyperClova(NAVER), Kanana(Kakao), MoMo(MOREH), Solar Pro Preview(upstage), N3N(N3N), 엑사원(LG AI 연구원),A.X(SKT),믿음(KT),바르코 LLM(NC소프트) 등이 잇따라 출시되었다.
그렇다면 이 수많은 LLM들 중에서 어떤 LLM이 좋은지는 어떻게 알 수 있을까 ? 저마다의 특성으로 인해 언어별, 분야별, 주제별로 각기 다른 장점을 지니고 있기 때문에 분야별로 유망한 LLM을 직접 찾아보고 검색해서 사용해봐야만 어떤 LLM이 좋은지 알 수 있을까 ? 다행히도 LLM의 기능들을 평가해주는 사이트가 존재한다. AI를 활용하여 데이터를 가공하고 사용할 수 있는 기반을 만들고자 하는 미국 기업, 세일즈포스에서는 CRM(Customer Relationship Manager, 고객 관계 관리)를 위한 LLM 평가 항목을 만들어서 전세계의 LLM을 평가하고 이 정보를 공개하고 있다. 더 나아가 이 데이터를 Hugging Face의 ✅ Open LLM Leaderboard에 제공해주고 있다. Open LLM 리더보드에는 여러 가지 LLM이 랭크되어 있고, 모델 별로 정확성(Accuracy), 지시 이행성(IFEval) 등에 관한 점수도 같이 기재되어 있다. 반면 국내의 LLM은 한국지능정보사회진흥원(NIA)와 Solar Pro Preview LLM을 만든 업스테이지사가 공동으로 주최하고 있는 ✅Open Ko-LLM Leaderboard에서 평가하고 있다. 여기서는 NIA가 한국어 LLM 모델 학습에 필요한 한국어 데이터셋을 제공하고 있으며 업스테이지사가 AI의 기능 평가를 담당하고 있다. ※ ('25. 6. 기준) Open Ko-LLM Leaderboard는 시즌 3를 위해 준비 중인 상태임.
하지만 정해진 범주 안에서 LLM을 테스트하게 된다면 특정 ⭐ LLM은 계속해서 학습이 가능하기 때문에 동일한 테스트를 반복해서 진행시킬수록 점수가 높아질 수밖에 없다는 단점이 있다. 실제로 위에 있는 Open LLM Leaderboard나 Open Ko-LLM Leaderboard에 들어가서 보면 생전 듣도보도 못한 LLM들이 1위에 랭크되어 있는 모습을 어렵지 않게 확인할 수 있는데, 이는 단순하게 높은 점수를 얻기 위해 평가 기관이 평가하는 부분에 맞춰 최대한 문제를 빠르고 정확하게 맞출 수 있도록 하는 데에만 집중해서 개발하면 높은 점수를 얻을 수 있기 때문에 일어나는 일이다. 또한 해당 LLM의 안정성이나 보안성, 창의성 등은 전혀 평가되지 않는다는 단점도 있다. 실제로 GPT-4나 Calude 3는 일부 모델들보다 낮은 점수를 가지고 있지만, 실제 사용 평가는 훨씬 우수한 것이 그 예이다.
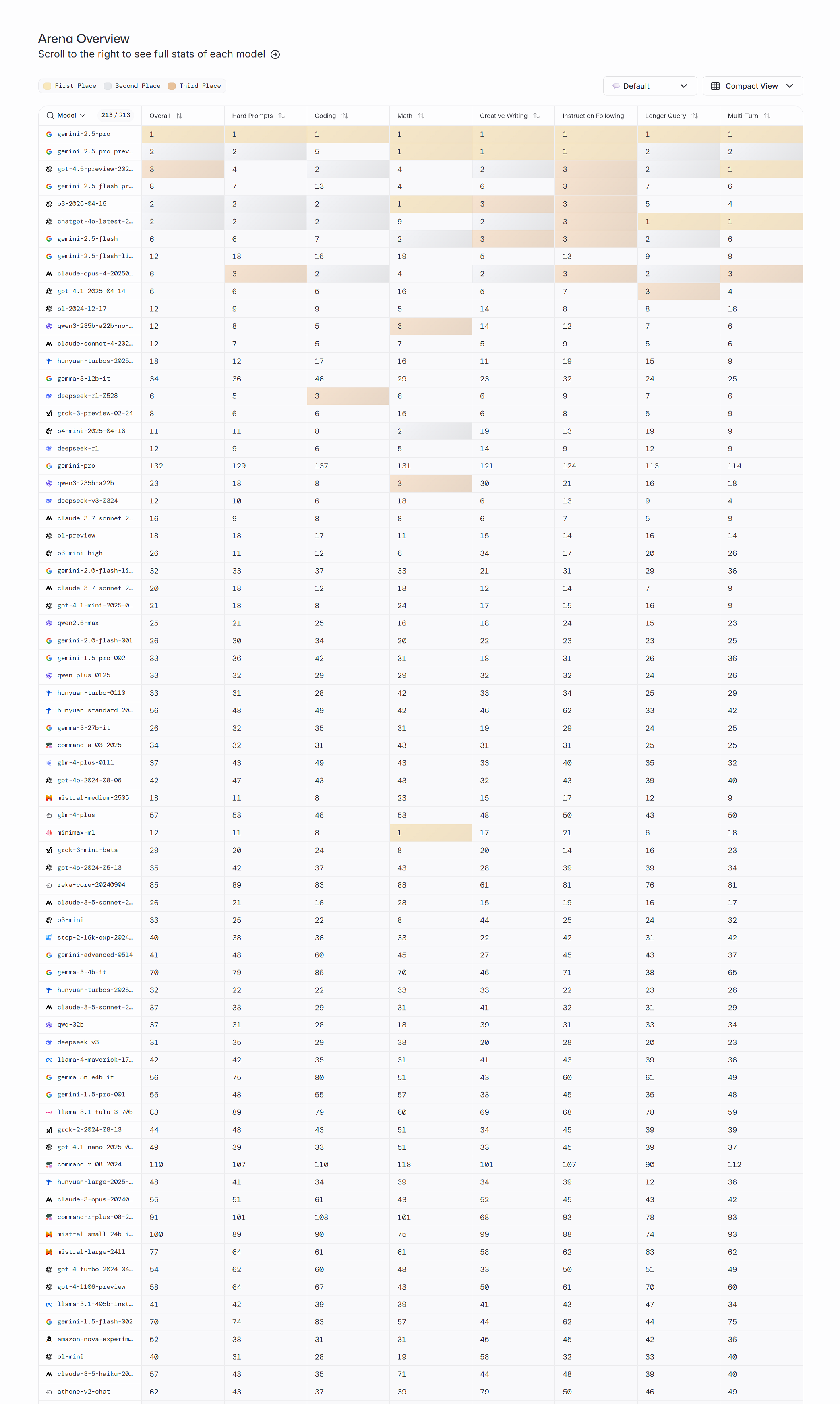
따라서 실제 사용을 목적으로 사용할 때 좋은 LLM이란 무엇인가를 알기 위해서는 사람의 평가를 기반으로 하는 랭킹을 확인하거나 주요 API들을 기반으로 비교한 자료를 확인해야 한다. 사람의 평가를 기반으로 랭킹을 나열하는 사이트로는 AlpacaEval, LMSYS Arena와 같은 사이트들이 있다. (사용자 평가를 기준으로 하기 때문인지 아쉽게도 한국의 LLM은 확인할 수 없었음) 2025년 6월 기준으로는 구글의 제미니 2.5 pro가 가장 높은 평가를 받고 있다.
(출처) LMSYS Arena, Arena Overview / (좌) 언어 기준, (우) 평가 항목 기준
이러한 평가 도구를 통해 어떤 LLM이 가장 좋은지보다, '내가 알고 있는 정확한 정보'를 LLM에게 물어보는 것이 그 성능을 확인할 수 있는 가장 정확한 평가 도구가 될 수 있다. 아래 이미지는 CLOVA X와 Chat GPT에게 동일한 내용을 질문하고 얻은 답인데, 답변의 방향성 뿐만 아니라 정확성까지 차이나는 것을 어렵지 않게 확인할 수 있다.
지금 현재 모두의 AI를 만들기 위한 프로젝트인 '독자적 AI 파운데이션 모델'이라는 프로젝트가 진행되고 있잖아 ? 근데 이거는 윤석열 정부 때부터 이어져오던 프로젝트를 이름만 바꾸고 내용을 수정(프로젝트 목표 달성 기간 단축 등)해서 진행하고 있는 것 같아. 그럼 이전에는 어떤 이름으로 진행되고 있었어 ? 원래의 내용을 알고 싶어.
[요구 사항]
① '독자적 AI 파운데이션 모델' 프로젝트의 과거 이름은 무엇인가 ? ② '독자적 AI 파운데이션 모델' 프로젝트는 과거에 어떤 내용을 갖고 있었나 ?
[답변 내용]
네이버의 CLOVA X는 지금 현재 '독자적 AI 파운데이션 모델'로 변경된 프로젝트에 대한 언급 없이, 소버린 AI가 모두의 AI라는 이름으로 변경되었다고 응답하고 있다. 이에 반해 Open AI의 Chat GPT는 소버린 AI나 모두의 AI라는 단어가 아닌 독자적 AI 파운데이션 모델이라는 단어를 중심으로 내용을 작성해나가고 있으며, 지금 현재 독자적 AI 파운데이션 모델이 과거 초거대 AI 프로젝트의 연장선이라고 응답하고 있다. 즉, 궁금했던 '이 프로젝트가 과거에 불리던 이름은 ?'이라는 질문에 대해 CLOVA X는 응답하지 못했고 Chat GPT는 응답하고 있는 것이다. 이렇게 직접 사용해보는 것도 LLM의 성능을 주관적으로 판단해볼 수 있는 좋은 방법이다.
LLM의 향후 전망은 ?
AI에는 물론 다양한 분야들이 존재하긴 하겠지만, 말마따나 지금 가장 핫한 아이템은 ✅ 생성형 AI, NLP(자연어처리)이다. 하지만 여느 아이템이던지 간에, AI라는 것은 기본적으로 사람의 언어를 이해하고 사람의 요청을 정확하게 분석하고 올바르게 인지할 수 있는 능력이 가장 중요시된다. 그 기반이 마련되어야만 그 위에서 무언가를 생성하던지 분석한 데이터를 가지고 새롭게 응용하던지 자동화 시스템을 만들어내던지 할 수 있기 때문이다. 더 나아가 만약 LLM을 만들어냈다면 이제 LLM으로 하여금 텍스트 데이터를 학습시켜야 하는데, 이 때 필요한 것이 AI 인프라(데이터센터 등)이다. AI 인프라의 경우에는 원전주 게시글을 참조
(시장 규모 예측) 캐나다 시장분석 기관인 프리시던스 리서치(Precedence Research)에서 내놓은 글로벌 AI 시장에 대한 보고서에 따르면 2025년 기준 전세계 7,575억 8,000만 달러(한화 약 1,033조원)인 시장 규모가 2034년에는 3조 6,804억 7,000만 달러(한화 약 5,020조원)
(누적 투자 현황) LLM이 얼마나 주목을 받는지를 알기 위해서는 LLM 주변에 모여든 자금의 흐름들을 보면 된다. 실제로 Open AI의 경우에는 마이크로소프트로부터 130억 달러(환율 1,380원 기준 한화 17.9조원) 이상의 투자를 유치했고, Anthropic은 아마존과 구글 등으로부터 약 70억 달러(환율 1,380원 기준 한화 9.6조원)를 유치했다. 이외에도 국내 기업 중에서는 의료 분야에서 AI를 기반으로 의료 영상을 분석하는 기술인 DIB(Data-driven Imaging Biomarker)를 활용하는 Lunit이 5.6억 달러(환율 1,380원 기준 한화 7,720억원)를 유치했고 교육 분야에서 AI를 기반으로 AI 튜터 솔루션을 서비스하는 Riiid는 2.5억 달러(환율 1,380원 기준 한화 3,380억원)를 유치하기도 했다.
(LLM 기업들의 가치 증가 속도) 가장 대표적인 LLM 기업인 Open AI는 '25년에 소프트뱅크 주도로 진행된 '스타게이트 펀딩'에서 59조원에 해당하는 펀딩에 성공했는데, 이 기업의 가치는 약 3,000억 달러(한화 약 414조원)에 해당한다. 이는 현재 스페이스 X(3,500억 달러, 483조원)의 뒤를 이어 비상장 기업 중 세계 2위에 해당하는 규모이며, 삼성전자의 시가총액이 '25년 6월 현재 400조에 해당한다는 점을 보면 2015년에 설립된 Open AI의 가치가 얼마나 미친 속도로 성장해왔는지 어렵지 않게 알 수 있다. 우리나라 비상장 기업 중 AI 분야에서 가장 유망해보이는 Upstage 사의 경우에는 누적 투자금액이 약 1,300억원이며 이를 토대로 기업 가치를 환산했을 때는 약 11조에서 12조 정도로 추정된다. 카카오뱅크와 삼성전기, 그리고 한국전력의 시가총액이 각각 11조, 11조, 13조에 해당한다는 점을 고려하면 이 기업의 가치가 어느정도인지 이해될 것이다. 참고로, 업스테이지는 2020년 10월에 설립됐다.
(글로벌 시장 진출) 최근 국내 LLM 기업들은 일본, 동남아 시장을 타겟으로 하여 사업 영역 확장을 시도 중이다. 업스테이지사의 Solar 만 해도 '24년 3월 경 미국에 현지법인 'Upstage AI'를 설립하였으며, 일본의 AI 솔루션 시장에 대해 CAGR이 47%보다 높은 수준으로 유지되어 '30년에는 17조원 규모로 성장할 것으로 보고 일본에 현지법인 'Upstage Japan'을 설립하여 일본어 특화 LLM을 개발하고 현지 기업을 파트너로 삼아 일본 시장에서의 영향력을 넓혀가기 위해 다방면으로 노력하고 있다.
그나저나 LLM은 돈이 되는 사업인가 ?
돈이 되는 사업인가에 대한 결론부터 말하자면 그렇다. LLM은 사실 LLM 자체로 판매되기도 하고, 이를 응용하여 기업의 효율성 향상을 유도하는 AI 응용 소프트웨어의 형태로 판매되기도 한다. 하지만, 명확하게 수익이 발생하고 있긴 하나 ✅ '대규모의 흑자 모델'은 아직 존재하지 않는다.
그 유명한 Open AI만 하더라도 2023년 기준 매출액이 20억 달러, 2024년 기준 매출액은 약 37억 달러인데 반해, 블룸버그에 따르면 2025년 예상 매출액은 무려 127억 달러(약 19조원)로 추정되며 2026년 매출액은 더 성장한 294억 달러(약 43조원)에 이를 것으로 전망된다고 한다. 하지만 GPT를 호출할 때마다 연산 비용으로 수십 ~ 수백 원의 비용이 지출되고 그 외에도 GPU 구매비용(또는 임차비용), 전기료 등의 비용이 많이 발생하기 때문에 흑자 전환에는 계속해서 실패하고 있다. 실제로 💬 오픈 AI가 흑자 전환이 가능한 시점은 매출이 1,250억 달러(약 183조원) 또는 1,000억 달러(약 130조원)을 넘어서는 2029년 이후에나 가능할 것으로 전망되고 있기도 하다. Open AI가 최근 Chat GPT 유료화와 더불어 LLM을 기반으로 한 또 다른 사업의 필요성을 느끼고 AI 에이전트 서비스를 개시하기 위해 노력하고 있는 것도 같은 맥락이다.
그렇다면 흑자 전환까지 오랜 기간이 걸림에도 불구하고 많은 기업들이 LLM을 개발하는 이유는 무엇일까 ? 일단 업무 자동화 효과와 같은 업무 효율성 증대가 가장 큰 이유겠지만, LLM 별로 특정 기업이 갖고 있는 기업의 데이터에 알맞은 작동 방식을 갖고 있어야만 더 높은 정확도를 보여주기 때문에 각자의 데이터에 알맞은 LLM을 개발하고 그를 바탕으로 사업의 효율화를 이뤄내고자 하는 목적도 있다. 인터넷 대표 기업인 네이버와 카카오만 하더라도 네이버의 Hyper CLOVA X는 뉴스, 검색, 그리고 스마트스토어 상 광고 지면 최적화 등의 기능을 수행하여 🤝 광고 및 커머스 전환율을 끌어올린다는 효과가 있는 반면, 카카오의 Kanana는 Open AI와 협력한다는 점에서도 알 수 있듯이 챗봇 등의 기능을 통해 AI를 사용자에게 보다 가깝게 밀착시켜서 💪 사용자를 보조하는 AI 에이전트로서의 느낌이 강하다.
즉, 단순히 'LLM은 돈이 된다.'라기 보다는 수익으로 돌아오기까지 기간이 오래 걸리는 고비용·고위험·고수익 사업에 해당한다. 따라서 투자하고자 하는 기업을 찾을 때, 단순히 LLM 자체를 사용하고 개발하는 기업에 투자를 하기 보다는 ✅ 그 기업이 LLM을 통해 어떤 문제를 해결할 수 있는지, 그리고 그 LLM을 통해 이뤄내고자 하는 목표가 무엇인지를 파악하고 그 목적 사업의 혁신성과 실현 가능성에 집중해야 한다.