AUTO TRADE/[키움증권] Kiwoom Open API
010. 파이썬 + MySQL, 파이썬으로 연동하기
반응형
지난 포스팅을 통해 설치와 설정하는 방법에 대해 다루었으므로 이번 포스팅에서는 파이썬 내에서 MySQL과 연결하는 방법과 사용방법에 대해 살펴볼 예정이다.
일단 이 MySQL은 앞전에서 다루었던 차트 데이터 조회에 대한 부분이 반드시 선행되어야만 아래의 내용들을 사용할 수 있기 때문에 아직 차트 데이터에 대한 코드 구축이 안 되어 있다면 그 글을 먼저 보고 넘어오도록 하자. 물론 차트 데이터 저장이 아닌 다른 목적으로 이용하고자 하는 경우라면 바로 읽어도 아무런 상관이 없다.
004. 키움증권 Open API 차트 데이터 불러오기 (1)
OnReceiveTrData 이벤트 처리하기지난 포스팅에서 Open API를 열고 로그인을 하는 코드까지 모두 구축하고 넘어왔다. 이번 포스팅에서는 로그인 이후에 조회하고자 하는 종목의 차트 데이터를 불러오
trustyou.tistory.com
그리고 내용을 알아보기 전에 앞서, 이번 포스팅에서 사용할 모듈은 sql alchemy와 mysql 두 개인데, 파이썬에서 설치하는 방법은 파이썬 prompt를 통해 pip install sqlalchemy, pip install mysql 등을 사용하면 된다. 다만 파이참에서는 이러한 모듈을 설치하는 것이 간단하지가 않기 때문에, 간략하게 설명하고 본론으로 들어가도록 하겠다.


먼저 파이참에서 왼쪽 상단의 [File] - [Settings] 메뉴를 클릭하면 창 하나가 뜨는데, 그 창에서 Project: 아래에 있는 Python interpreter를 클릭하자. 그러면 위의 오른쪽에 있는 사진과 같은 화면이 나오게 되는데, 하단 좌측에 있는 + 버튼을 클릭하자.
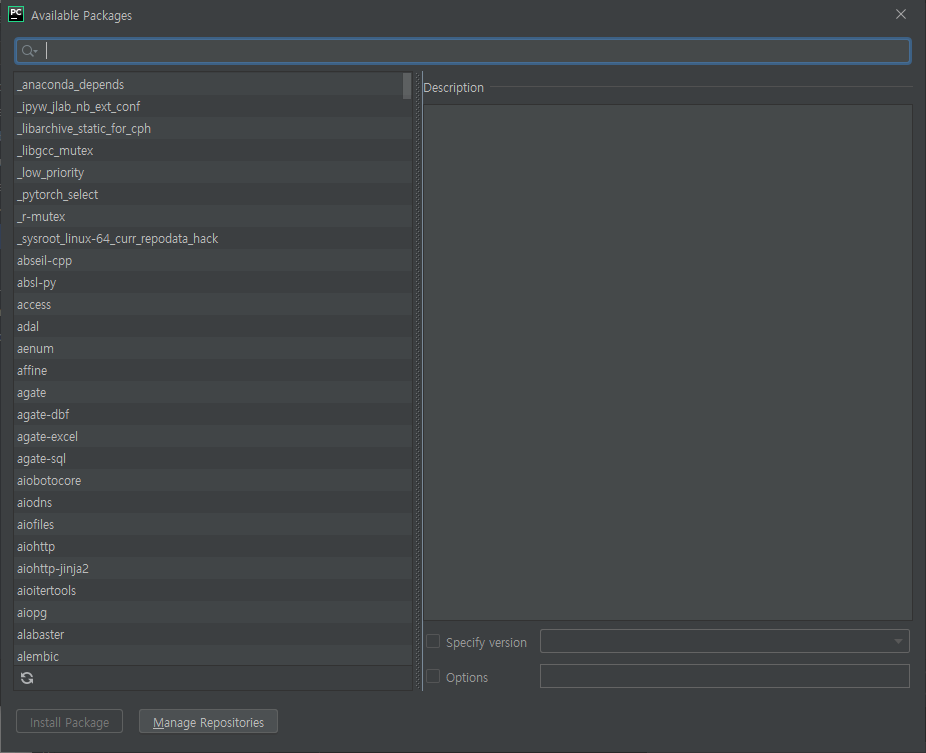
위의 검색 화면에 sqlalchemy와 mysql을 검색한 후에 각각 하나씩 설치를 해주면 된다. 설치 버튼은 하단 가장 좌측에 위치한 install package를 클릭하면 알아서 설치를 시작한다.

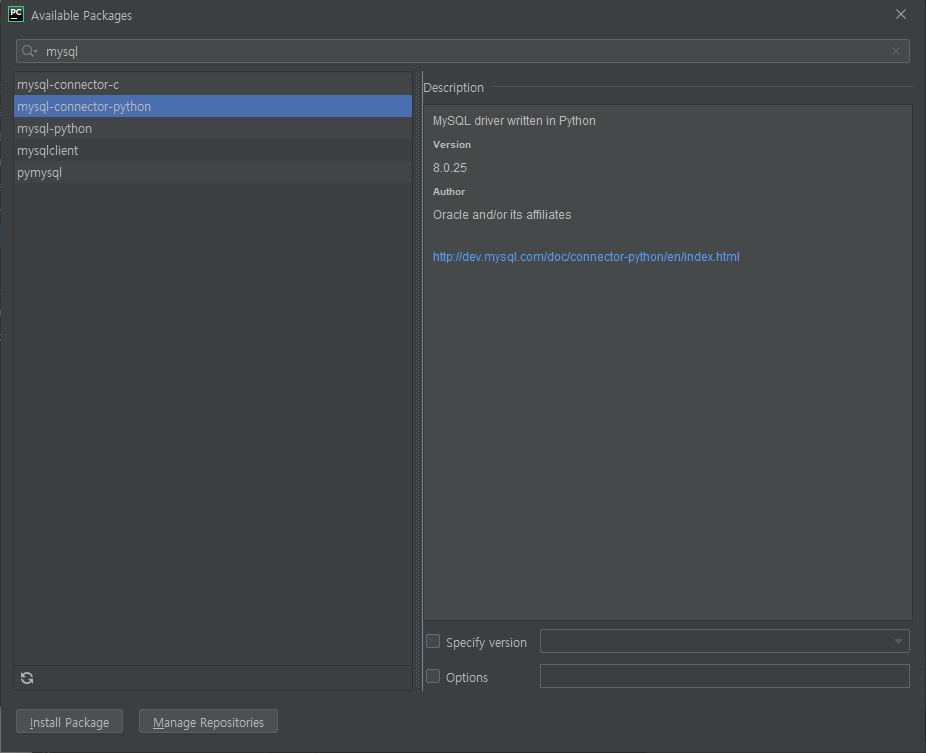
sqlalchemy는 sqlalchemy를 설치하면 되고, mysql은 mysql-connector-python과 mysql-python을 설치해주면 된다.
파이썬에서 MySQL 연결하기 - SQL alchemy
파이썬 내에서 MySQL을 연결하는 데에는 두 가지 방법이 있는데, 지금부터 하나하나 살펴보도록 하자. 먼저 첫 번째 방법은 SQL alchemy를 통해 연결하고 데이터를 손쉽게 보내는 방법이며, 두 번째 방법은 mysql.connector를 이용해서 연결하고 DB를 생성 및 제거하는 방법이다. 먼저 첫 번째 방법인 SQL alchemy부터 알아보도록 하자. 이 SQL alchemy는 앞서 Open API와 관련된 코드가 제작되어 있는 파일에 제작해도 되고, 별도로 관리하고 싶다면 그 밖에 새로운 파일을 만들어서 새롭게 제작해도 된다. 따로 제작하더라도 Open API 코드가 있는 파일에서 `import` 함으로써 우리가 제작한 코드들을 사용할 수 있기 때문이다.
1. import sqlalchemy
여러 번 살펴봤던 내용이지만, 모듈을 사용하기 위해서는 import를 해야만 하며 해당 모듈 내에 있는 함수를 사용하기 위해서는 모듈 이름.함수 이름을 사용하면 된다고 설명했었다. 이 경우에는 아래와 같이 코드를 작성하면 된다. 즉, 이 함수는 mysql과 연결하기 위해 사용하는 함수이다.
from sqlalchemy import create_engine
2. engine 구축하기
여기서의 엔진은 위에서 import 했던 MySQL과 연결할 수 있는 코드를 의미하며, 아래와 같은 형태로 이루어진다.
- engine = create_engine('mysql+mysqldb://root:password@127.0.0.1:3306/DB_name', encoding='utf-8')
앞에 있는 password는 이전 포스팅에서 설정했던 값이고, 그 뒤에 있는 DB_name은 아래에서 제작할 예정이다. 그 뒤에 encoding='utf-8'은 간혹 DB 내에 한국어를 입력할 경우 인코딩하는 데에 있어서 오류가 발생하는 경우가 있기 때문이다. 인코딩 방식을 utf-8로 설정하게 되면 한글을 입력할 때에도 오류가 발생하지 않는다. 이처럼 engine이라는 변수를 제작한 뒤에는 engine.connect()를 사용함으로써 입력했던 DB_name과 연결시킬 수 있다. 이를 코드로 작성하면 아래와 같은 형태의 코드를 구축할 수 있다.
from sqlalchemy import create_engine
engine = create_engine('mysql+mysqldb://root:password@127.0.0.1:3306/DB_name', encoding='utf-8')
connection = engine.connect()
3. Pandas의 to_sql과 engine 사용하기
다음으로 우리가 차트 데이터를 조회할 때 제작했던 코드를 보면, if문 아래에서 day_data라는 변수에 저장되어 있는 차트 데이터들을 pandas.DataFrame 함수를 통해 데이터프레임 형태를 갖추도록 자료를 가공한 후 df_day_data라는 변수에 대입하였다. 이제 이 df_day_data를 MySQL에 전송할 수 있는데, 그 코드의 기본 골격은 아래와 같다.
- df_day_data.to_sql(name=, con=, index=, if_exists=)
파라미터에 대해 하나 하나 설명해보도록 하겠다. 가장 먼저 두 번째 파라미터인 `con`은 connection의 줄임말로 어떠한 engine을 사용할 것인지를 입력해주면 된다. 우리가 위에서는 engine을 DB_name이라는 데이터베이스와 연결했지만, 실제로 데이터를 처리하다보면 하나의 데이터베이스 안에서 모든 것들을 처리하기에는 어려운 점들이 있다. 그렇기 때문에 여러 개의 데이터베이스를 제작하고 사용하게 되는데, 그럴 경우에는 저장하고자 하는 DB 이름을 입력한 engine을 사용해주어야 그 DB 안에 하나의 테이블을 만들고 데이터들을 입력하게 된다. 다음으로 name은 테이블 명이다. 도대체 테이블이니 데이터베이스니 뭐니 정말 헷갈릴 수도 있을 것 같아서 아래의 그림을 만들어왔다.
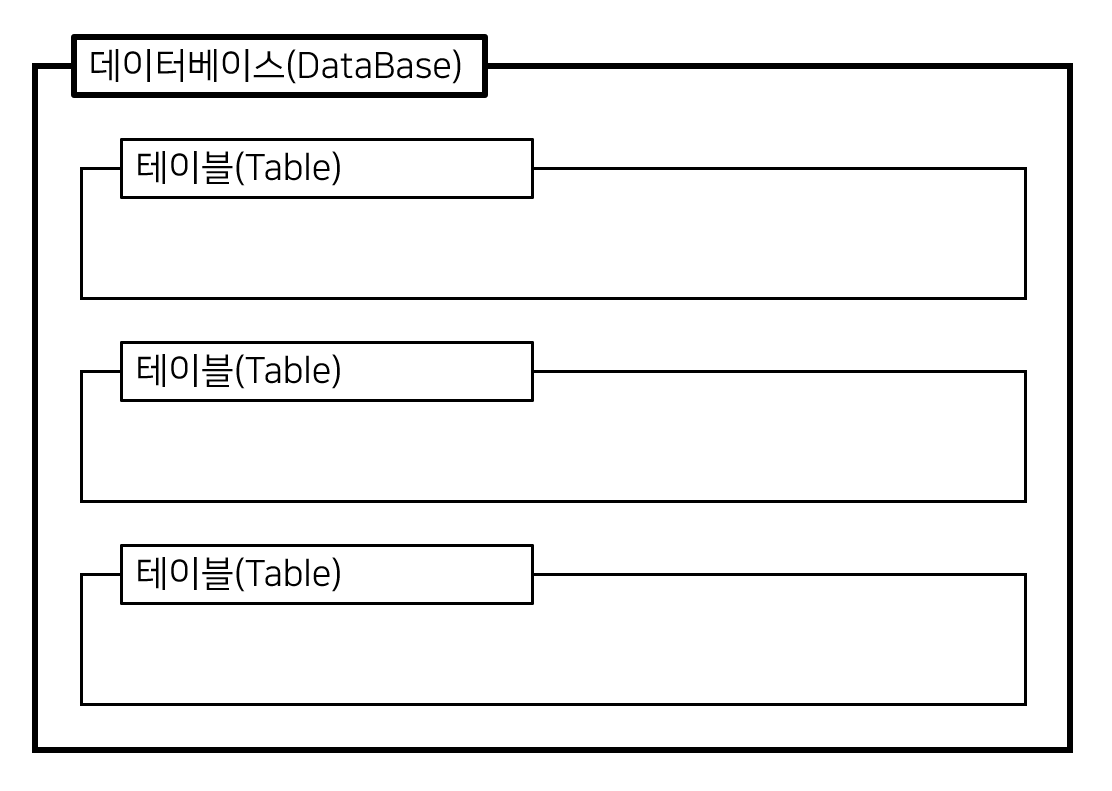
즉, 위의 도식에서 데이터베이스라고 적혀 있는 부분이 우리가 engine을 구축할 때 사용한 DB_name에 해당하는 부분이고, 그 아래에 있는 테이블이 우리가 to_sql을 사용할 때 name=에 해당하는 부분이다. 아직 이해가 잘 되지 않을 수도 있으니, 아래와 같이 실제로 본인이 데이터들을 어떻게 저장했는지 그 형태를 만들어 왔다.
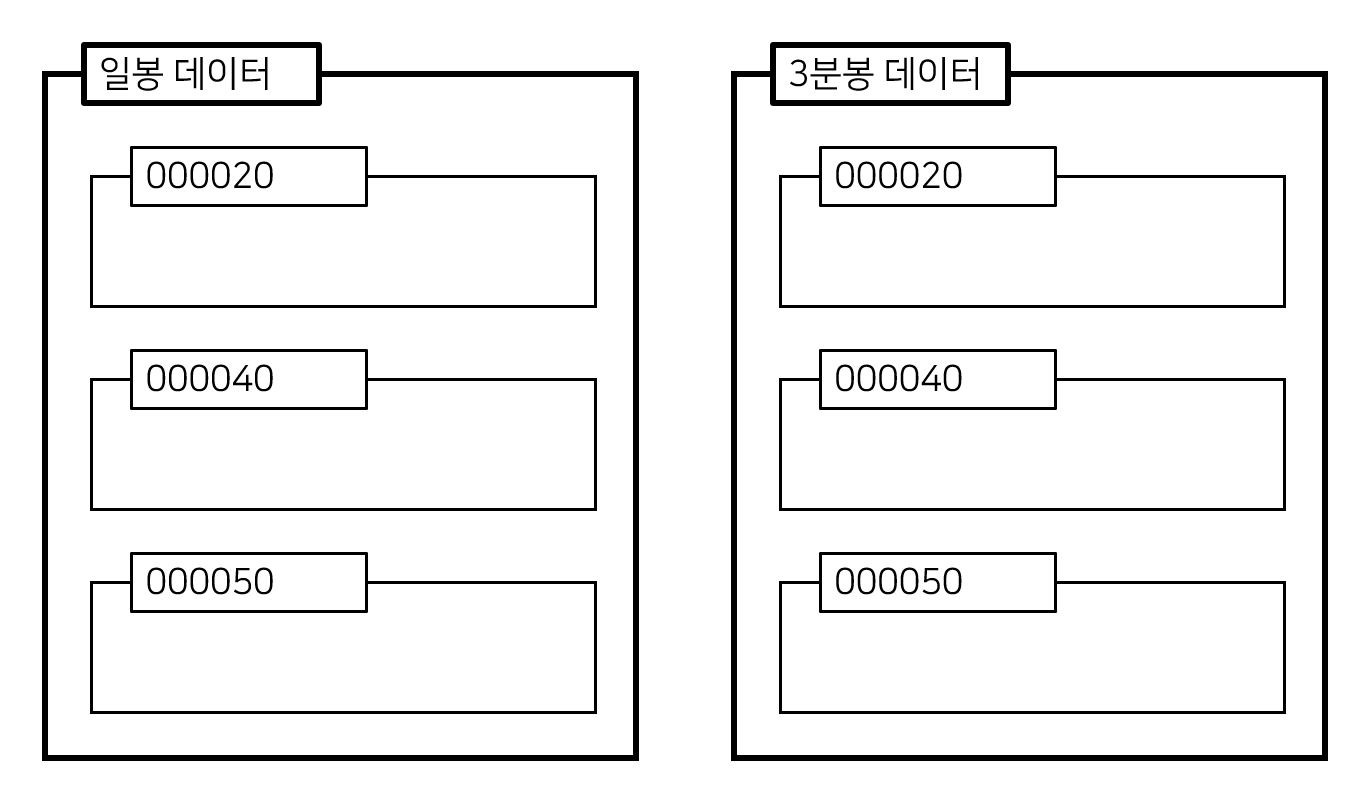
즉, 데이터베이스가 여러 개인 구조이다. 물론 이처럼 데이터베이스가 일봉 데이터와 분봉 데이터를 구분하지 않고 데이터베이스를 000020 등의 종목 코드로 놓고 그 안에 있는 테이블 이름을 day_data와 min_data와 같은 식으로 구분할 수도 있다. 그런 부분들은 어디까지나 개인의 자유이고 본인의 선택에 따라 사용하면 된다. 다만 잊지 않아야 하는 부분은 바로 engine을 만들 때에는 데이터베이스의 이름을, to_sql을 사용할 때에는 name= 구간에 우리가 저장하고자 하는 테이블의 이름을 입력해주면 된다는 것이다. 위의 사진을 예로 들면 engine을 구축할 때에는 '일봉 데이터'를, to_sql을 사용할 때에는 name='000020'과 같은 형태로 구축해야 하는 것이다.
다음으로 index=는 말 그대로 인덱스인데, 사실 백테스팅을 하거나 할 때는 크게 중요한 역할을 하지는 않는다. 이러나 저러나 자료는 어떤 식으로는 활용할 수 있으니 만약 인덱스가 뭔지 궁금하다면 구글에서 검색해보도록 하자. 본인 역시 인덱스가 뭔지 알고 있긴 하지만, 다 찾아보고 직접 사용해보니 굳이 설명할 실익이 없다는 생각이 든다.
마지막으로 if_exists=는 말 그대로 '만약에 존재한다면'이라는 의미이다. 이 파라미터 뒤에 입력할 값으로는 replace(교체) 또는 append(이어서 입력)이 있다. if_exists='replace'로 구축을 하게 되면 이전에 입력되어 있던 데이터들은 모두 삭제된 후에 새롭게 입력하는 데이터만 들어가게 된다. 즉, 중복이든 뭐든 상관 없이 '삭제 - 입력'의 절차를 거친다고 보면 된다. 다음으로 if_exists='append'는 이전에 입력되어 있는 데이터가 있든지 없든지 간에 일단 '입력'하고 본다. 즉, replace와는 다르게 '삭제'라는 절차 없이 '입력'만 하는 것이다.
여기까지 크게 어려운 부분이 없을 것인데, 정말 마지막으로 이해 차원에서 본인이 사용 중인 코드를 첨부한다. 실제로 어떻게 사용하고 있는지 이해하기 위한 측면이니, '이게 맞다 틀렸다'라는 생각보단 그냥 '아. 저렇게 쓰는구나.'정도로만 이해하고 넘어가도록 하자.

728x90
mysql.connector() 사용 방법
mysql.connector()를 통해 데이터베이스를 만들거나 삭제하거나 할 수 있는데, 우리는 위에서 DB와 연결하는 방법에 대해 살펴봤었다. 곰곰이 생각해보면, DB가 없는데 연결할 방법이 없다. 즉, 바로 위에 첨부한 사진처럼 engine을 구축하기 전에 앞서 우리는 데이터베이스를 만들어야만 한다. 다시 말해, 데이터베이스를 생성하고 존재하는지 그 여부를 확인하는 절차가 위의 절차보다 먼저 와야 한다는 것이다. 그렇다면 mysql.connector()는 어떻게 사용하는가?
1. import mysql.connector
import mysql.connector이 부분에 대한 설명이 필요할까 싶다.
2. connection 구축하기
connection의 경우에는 sql alchemy에서 engine을 만들었던 것과 마찬가지로 DB에 연결을 해주는 것인데, 살짝 다르다. engine은 DB에 연결을 해주지만 mysql.connector는 DB가 아니라 MySQL에 연결을 해준다. 무슨 말인지 이해가 가는가? 다시 말해, mysql.connector를 통해 MySQL에 연결할 수 있기 때문에, 데이터베이스가 없어도 연결이 가능하다는 이야기이다. 앞서 살펴봤던 engine은 MySQL 안에 데이터베이스가 있어야만 동작하지만, mysql.connector는 MySQL에 연결할 수 있기 때문에 데이터베이스가 없어도 동작할 수 있다. 이 점을 통해서 우리는 mysql.connector를 가지고 DB를 만들고 삭제할 수 있다. 이 코드의 기본 구조는 아래와 같다.
- connection = mysql.connector.connect(user="root", password="", host="127.0.0.1", charset="utf8mb4")
사실 별다른 구조를 살펴볼 필요도 없는게, 그냥 비밀번호만 입력하면 MySQL에 로그인되는 것이다. 위에서 살펴봤던 engine과는 달리 데이터베이스의 이름을 따로 지정하는 구간이 없지 않은가? 이제 패스워드 칸에 비밀번호를 입력해준 후에, cur = connection.cursor()라는 코드를 통해 MySQL에 로그인하도록 한다.
connection = mysql.connector.connect(user="root", password="", host="127.0.0.1", charset="utf8mb4")
cur = connection.cursor()
3. DataBase 생성하기
위에서 cur라는 변수를 생성했는데, 사실 여기에는 굳이 cur가 안 들어가도 되고 뭐든 입력해도 된다. 다만 본인의 입맛대로 바꾼다 하더라도, 첫 번째 줄에 있는 connection이 두 번째 줄에 있는 connection.cursor()에 또 다시 쓰였다는 부분들을 함께 매칭시키면서 바꿔야 코드가 오류없이 작동할 것이다.
다시 본론으로 돌아와, 혹시 execute라는 영단어를 아는가? 이는 '실행하다'라는 의미이다. 우리는 DataBase를 생성하거나 삭제하거나 할 때 특정한 명령문들을 입력하게 되는데, 그 기본 형태는 아래와 같이 작성된다. 또는, 명령문을 하나의 변수로 입력한 후에 그 변수를 실행하도록 할 수도 있다. 아래의 코드를 참고하자.
# 바로 입력
cur.execute("~~~~~~~~~~~")
# 변수로 입력
rule = "~~~~~~~~~~~~~"
cur.execute(rule)이제 데이터베이스를 생성하거나 삭제하기 위해서는 CREATE, DROP이라는 명령어를 알아야 한다. 사실 영어 그대로 해석하면 '만들다.', '버리다.'라는 의미이기도 해서 별 다른 설명이 필요 없을 것 같다.
만약 데이터베이스를 생성하고 싶다면 CREATE DATABASE 'DB_name'을, 데이터베이스를 삭제하고 싶다면 DROP DATABASE 'DB_name'을 입력한 후에 cur.execute()에서 괄호 사이에 넣어주기만 하면 알아서 실행한다. 여기서 주의해야 할 점이 있다면, DB_name의 양 옆을 감싸고 있는 점이 있는데 여기에는 일반적인 키보드에서 엔터키 옆에 있는 '(작은 따옴표)가 아니라, Tab 버튼 위에 있는 백틱(backtick)dmf 사용해야 한다. 왠진 모르겠지만, '(작은 따옴표)를 사용하면 정상적으로 동작하지 않는다. CREATE 또는 DROP을 사용할 때 발생하는 오류들 중 대부분은 '와 `를 잘못 입력했을 때 발생한다.
예를 들어 우리가 all_data라는 데이터베이스를 생성하거나 삭제하고 싶다면 아래와 같이 입력하면 된다.
cur.execute("CREATE DATABASE `all_data`")
cur.execute("DROP DATABASE `all_data`")
4. DataBase 있는지 확인하기
예전에 본인의 경우에는 키움증권 OpenAPI를 실행시킬 때, 본인이 제작한 코드에서 요구하는 모든 DataBase가 구축되어 있는지 확인하고 만에 하나 없는 DB가 있다면 새롭게 제작한 후에 OpenAPI가 실행되고 로그인되도록 해두었다고 서술했었다. 즉, 위의 모든 내용에서 CREATE와 DROP의 사용 방법을 익히고 engine 등을 모두 구축했다 하더라도 이 SHOW 없이는 자동적으로 처리하도록 하는 코드의 구축이 힘들다. 눈치가 빠른 분들은 이미 눈치채셨겠지만, 이 SHOW도 사용법은 단순하다.
cur.execute("SHOW DATABASES LIKE `all_data`")그리고 이 내용은 다음 시간에 다룰 내용이었는데, 해당 명령어를 실행한 후에 반환되는 값이 있는 경우에는 fetchone() 또는 fetchall()을 사용한다. 즉, cur.execute()를 사용한 후에 cur.fetchall() 또는 cur.fetchone()을 사용해야 데이터를 가져온다는 것이다. fetchone()은 맨 위에 한 줄만, fetchall()은 데이터 전체를 불러오는 것이다. 갑자기 이 이야기를 왜 하는가 할 수도 있는데, 바로 데이터베이스가 있는지 확인하는 명령문인 SHOW의 결과를 가지고 와야 하기 때문이다. 이 경우에는 fetchall()을 사용하면 되고, 그 결과를 변수에 대입한 후 그 변수를 출력해보면 존재 여부를 확인할 수 있다. 만약 반환값의 개수(개수를 확인하는 방법은 len()을 사용하면 된다)가 0이라면 해당 데이터베이스는 존재하지 않는 것이고, 0이 아니라면 해당 데이터베이스가 존재하는 것이다.
cur.execute("SHOW DATABASES LIKE `DB_name`")
result = cur.fetchall()
print(len(result))
따라서 만약에 'test'라는 데이터베이스에 대한 자동처리를 구축하고 싶다면 코드를 아래와 작성할 수 있다.
cur.execute("SHOW DATABASES LIKE `test`")
a = cur.fetchall()
if len(a) == 0:
cur.execute("CREATE DATABASE `test`")
else:
pass
728x90
반응형
'AUTO TRADE > [키움증권] Kiwoom Open API' 카테고리의 다른 글
| 012. 키움증권 Open API + MySQL, 차트 데이터 저장하기 (0) | 2021.06.06 |
|---|---|
| 011. 파이썬 + MySQL, 데이터베이스 자동 처리하기 (3) | 2021.06.06 |
| 009. 파이썬 + MySQL, 설치와 설정 방법 (0) | 2021.06.03 |
| 008. 키움증권 Open API - 조건 검색식 불러오기 (0) | 2021.06.01 |
| 007. 키움증권 Open API 전체 종목 리스트 불러오기 (0) | 2021.06.01 |
Contents
소중한 공감 감사합니다