AUTO TRADE/Back test
백테스팅 방법론
반응형
이번 게시글에서는 백테스팅을 진행하는 과정에 있어서 여러 가지 알고리즘들을 생성하게 될텐데, 그 과정에서 고려해야 하는 요소에 대해 다루어보고자 한다. 목차는 다음과 같으며, 목차를 클릭하면 해당하는 내용으로 들어가게 된다. 백테스팅 시에는 예상외로 고려해야 할 부분들이 많고 소제목 하나 하나의 내용이 길기 때문에, 차분하게 천천히 읽어나가길 권합니다.
※ 퍼갈 경우 반드시 출처를 표기해주시기 바랍니다.
[목차]
백테스팅의 의의
"시점이 중요하다". 시점을 기준으로 데이터를 나누어 살펴보아야 한다.
백테스팅 시에는 나타나지 않는 실 거래의 문제점
백테스팅 시에 사용하는 알고리즘이 올바르게 동작하는지 확인해야 한다.
필요한 데이터를 모두 입력하고 확인하라.
백테스팅의 의의
백테스트(Back-test)는 기본적으로 지난 날의 주가 데이터를 기반으로, 특정 알고리즘의 유효성을 판단하거나 알고리즘에 따라 진행되는 거래 지점을 수정하는 데에 가장 유용하게 사용되는 수단이다. 다만, 알고리즘을 손쉽게 수정하기 위해 알고리즘 내에서는 반드시 거래 조건들을 수정할 수 있도록 변수화해두어야 한다. 예상외로 다양한 데이터들이 변수화되어 있지 않고 그때마다 직접 설정해줄 경우에는 추후 수정할 경우 해당 변수를 직접 다 찾아서 수정해주어야 하므로 수정이 어려울 뿐만 아니라 한다고 하더라도 상당한 시간이 소요된다.
또한 그 값도 입력할 때에는 간편하게 하기 위해 알고리즘 내에서 입력된 값을 특정 값으로 변경할 수 있도록 하는 것도 필요하다. 예를 들어 전체 상승폭을 10등분하여 매수 지점을 설정한다고 했을 때, 5라는 값을 입력하면 50%에서, 6이라는 값을 입력하면 60%에서, 5, 6을 입력하면 50%와 60%에서 분할 매수가 이루어지도록 하는 것이다. 여기서 50%와 60%에서 분할 매수가 이루어진다고 하면 사전에 설정한 알고리즘 별 매수 가능 금액의 비율도 설정해주어야 한다. 즉, 50%에서는 매수 가능 금액의 0.4(40%)만큼 매수하고 60%에서는 매수 가능 금액의 0.6(60%)만큼 매수하도록 하는 것이다. 이같은 세부적인 요소들은 반드시 변수화하여 해당 변수만 수정했을 때 곧바로 적용되도록 하는 부분을 항상 고려하여 코드를 구축해야 한다.
만약 이 부분을 손쉽게 수정할 수 없다면 본 알고리즘의 유효성과 거래 성과를 판단하고 그를 수정 및 보완하기 위한 수단인 백테스팅으로서의 역할을 제대로 수행할 수 없게 된다. "백테스팅은 알고리즘을 위한 존재다."라는 부분을 잊지 말자. 모든 정보들은 알고리즘을 위해 존재하며, 알고리즘은 실제 거래의 성공률과 수익률을 높이기 위해 존재한다.
"시점이 중요하다." 시점을 기준으로 데이터를 나누어 살펴보아야 한다.
백테스팅을 진행하는 방법은 여러 가지 방법들이 있지만, 가장 기본적으로 갖춰야 하는 부분은 "시점"이다. 이 시점을 제대로 구분해서 데이터를 생성하고 그걸 응용해야만 추후 복잡한 절차를 거치지 않고 알고리즘을 그대로 실제 거래에 적용할 수 있다. 예를 들어 2019.12.23부터 2022.05.27까지의 일봉 차트 데이터가 있다고 가정해보도록 하자.
0 20220527 11950 12000 11800 11850 111027 1315669950 1 20220526 11800 12050 11800 11850 73542 871472700 2 20220525 11850 12000 11750 11800 79303 935775400 : (중략) : 595 20191230 8110 8420 8110 8310 198584 1650233040 596 20191227 8010 8150 7980 8140 57641 469197740 597 20191226 8160 8160 8000 8000 318154 2545232000 598 20191224 8140 8180 7990 8150 150877 1229647550 599 20191223 8120 8240 8000 8150 115949 944984350
이 데이터를 기반으로 백테스팅을 하기 위해서는 어떤 내용이 필요할까? 바로 매수 예정 가격과 매도 예정 가격 등과 같은 거래 데이터들이다. 하지만 거래 데이터는 어떤 시점을 기준으로 하느냐에 따라 다른 결과값들이 산출되기 마련이다. 다시 말해, 백테스팅을 할 때에는 "특정 일자"를 기준으로 하여 몇 가지 기준(종목 선정 기준)에 의해 산출된 "특정 종목"의 "거래 데이터"를 우선적으로 생성해야 한다는 것이다. 백테스트의 의미를 떠올려보면 "이전의 주가 데이터를 기반으로 개인의 알고리즘에 따라 거래를 진행했을 때 어떤 성과를 내는지"를 살펴보는 것이다. 아래의 도표를 예로 들어 시점을 나누는 방법에 대해 구체적으로 살펴보도록 하자.

만약 백테스트를 진행하고자 하는 현재 시점이 초록색 선(NOW)을 의미한다면, 우리는 A, B, C 중 어떤 지점이든 간에 상관 없이 모든 지점을 기준으로 해서 백테스트를 진행할 수 있다. 다만 중요한 것은 특정 지점을 설정했다면 반드시 해당 지점까지의 데이터를 기반으로 한 거래 데이터를 생성해야 한다는 것이다. 만약 A 지점을 기준으로 해서 백테스팅을 진행하기로 했다고 가정하고 살펴본다면, 중간 지점의 모든 정보를 제거한 상태에서 매수 예정가를 계산해야 할 것이다. 아래의 도표를 살펴보도록 하자.
그렇다면 우리는 반드시 컴퓨터에게 A 시점 이후에 대한 데이터를 결코 알려주어서는 안 될 뿐만 아니라 우리 스스로도 A 시점 이후의 데이터에 대한 정보를 알아서는 안 된다. 다시 말해, 컴퓨터에게 데이터를 기반으로 "이 데이터를 기반으로 했을 때 어디서 사!"라는 데이터를 우리의 알고리즘으로 생성해주어야 한다는 것이다. 만약 어찌저찌 알고리즘을 생성했고, 그 알고리즘을 기반으로 매수가와 매도가를 결정했다고 가정해보도록 하자. 그렇다면 그 가격은 항상 고정된 가격인가, 아니면 이후의 주가 흐름에 따라 변동될 수 있는 가격인가를 살펴보아야 한다. 만약 고점 대비 몇 % 하락했을 때 매수하는 알고리즘을 설정했다면 A 시점 이후에 주가가 추가적으로 상승할 경우 매수 지점 역시 달라지게 되기 때문이다. (이 부분은 알고리즘 편에서 살펴보자.)
다시 본론으로 돌아와서, 시점을 나누어야 하는 궁극적인 이유는 바로 우리가 맨 처음에 살펴봤던 도표를 보면 단번에 이해할 수 있을 것이다.
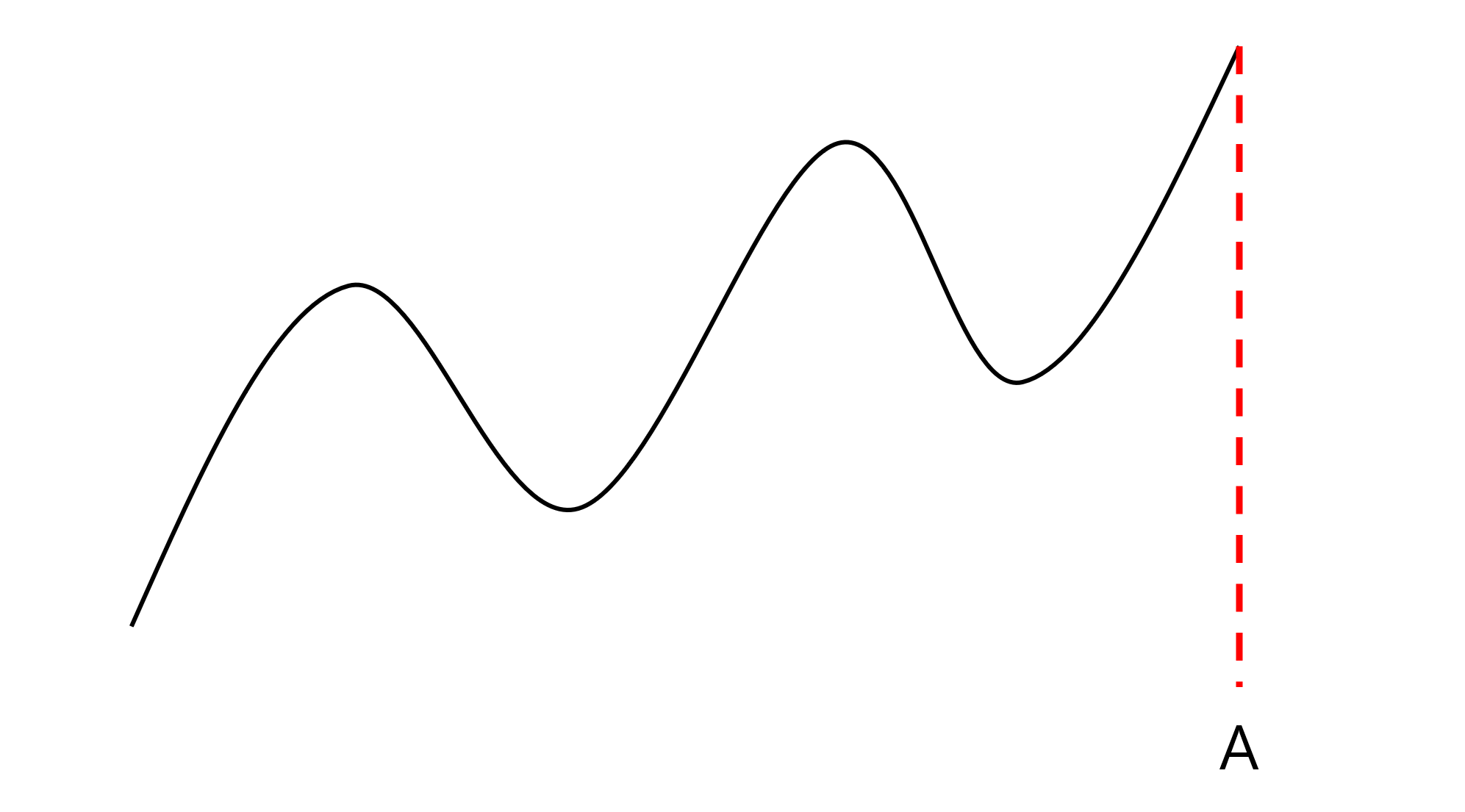
왼쪽의 도표는 백테스팅을 진행하고자 하는 현재 시점(NOW)에서 이전 시점(A or B or C) 중 하나를 선택해서 매수 예정가와 매도 예정가 등의 거래 데이터를 생성한 후 이후의 주가 흐름을 하나 하나 컴퓨터에게 알려주면서 사고 파는 행위를 하도록 하는 것이지만, 실제 알고리즘은 오른쪽의 도표와 같이 현재 시점이 곧 백테스팅을 진행하게 되는 시작점(A)과 같은 역할을 수행한다. 즉, 알고리즘에 의해 매수가와 매도가를 계산하는 것은 반드시 분석하고자 하는 시점을 기준으로 하여 그 이전의 데이터만 사용해야 한다는 것이다.
이는 다른 말로 설명해보자면, 백테스트를 진행할 때에는 매수 예정가와 매도 예정가 등의 거래 데이터와 그를 기반으로 하여 백테스트를 진행하는 알고리즘은 명명백백하게 분리되어 있어야 한다는 것이다. 아래의 도표를 살펴보자.
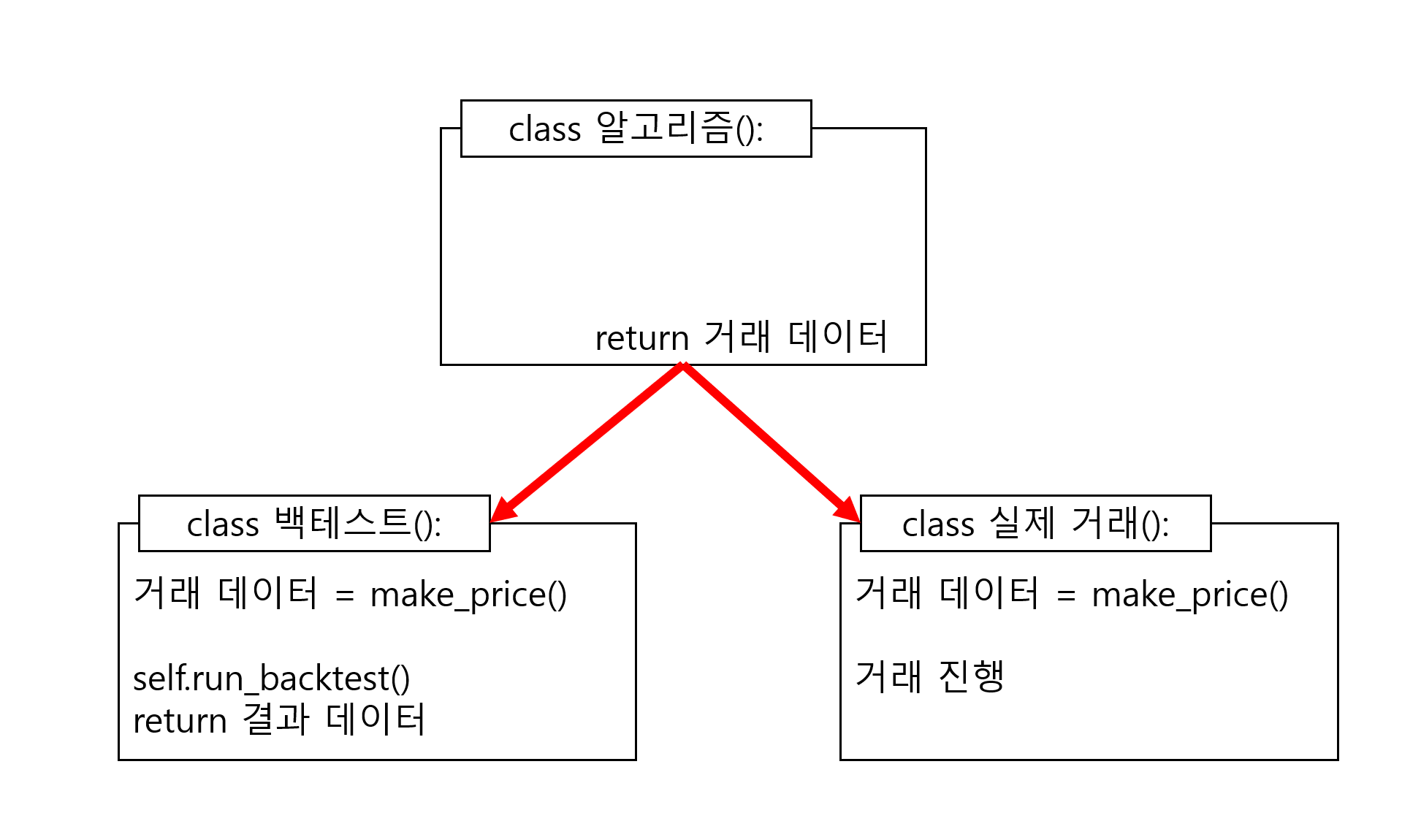
위와 같이 특정 알고리즘은 매수가와 매도가만 산출하는 형태의 알고리즘을 갖춰야 한다. 즉, 알고리즘에서는 매수가와 매도가만 계산하는 역할을 수행하므로 백테스트 클래스 에서는 일봉 데이터가 있다고 할 때 특정 시점까지의 일봉 데이터만을 알고리즘에 전송해준 후에, 전달받은 거래 데이터 를 기반으로 이후의 데이터에 적용하여 백테스트를 진행하면 되고, 실제 거래 클래스 에서는 딱히 나누어줄 시점이랄 게 없으니 그냥 서버로부터 전달받은 일봉 데이터 전부틑 전달해서 거래 데이터 를 얻어와 그 데이터를 기반으로 거래를 진행하면 되는 것이다.
728x90
백테스팅 시에는 나타나지 않는 실 거래의 문제점
알고리즘에 의해 게산된 데이터가 백테스팅시에는 나타나지 않지만 실 거래 시에는 나타날 수 있는 문제점으로는 여러 가지가 있는데, 그 중 대표적인 내용 중에 하나가 바로 여러 개의 알고리즘을 사용할 때 나타난다. 즉, 여러 개의 알고리즘에 의해 산출된 거래 데이터를 합쳐놓고 보니, 한 개의 종목에 대해 여러 개의 매수 매도 지점이 생성되는 것이다. 이외의 문제점들은 대체로 가벼운 코드 수정만으로 해결할 수 있는데, 여러 개의 알고리즘을 제작해서 사용하다 보면 한 개의 종목에 대해 여러 개의 매수 지점이 생성되는 경우들이 있는데, 본인의 경우만 하더라도 하나의 알고리즘에서 두 개의 매수 지점을 산출해내어 거래를 진행하고 있기 때문에, 두 개의 알고리즘만 겹치게 되면 총 4개의 매수 지점이 발생하게 된다.
이를 해결하는 방법은 알고리즘 별로 추구하는 거래의 디테일을 조금 더 정확하게 살리는 것이며, 이는 백테스팅을 통해 실현할 수 있다. 만약 ①강한 상승 이후에 급격한 하락을 노리고 매수에 가담하는 것과, ②강한 상승 이후에 적당한 조정을 노리고 매수에 가담하는 것은 실질적으로 매수 지점은 동일할 수도 있으나 엄밀히 따지고 보면 "기간"이나 "하락 시의 변동성" 내지는 "하락 시의 거래량" 등과 같은 세부적인 디테일에 있어서 차이가 발생한다. 이 부분을 백테스팅을 통해 보다 세부적인 데이터를 생성하여 분석하고, 그를 알고리즘 내에 녹여내는 것이 반드시 필요하다.
뿐만 아니라 백테스팅 시에는 실 거래와는 달리 무조건 빠질 수밖에 없는 부분이 있는데, 바로 "대내외적 이슈로 인한 지수의 변동 및 시장의 흐름"이다. 이는 백테스팅과 실 거래 간에 괴리가 발생할 수밖에 없는 가장 큰 요인으로 작용하나, 실 거래에서 이러한 요인을 고려하지 않고 거래를 진행하는 트레이더에게는 논외일 수 있다.(개개인에 따른 차이가 있을 수 있지만, 시장의 흐름을 무시한 채 진행되는 거래는 기본적으로 유효하지 못하다. 좋은 성과를 낼 수도 있겠지만, 여러 흐름을 고려한다면 더 좋은 성과를 낼 수 있으며 본인 역시 그렇게 믿고 있으며 실제 여러 트레이더들의 의견도 그러하다.)
반대의 경우
마찬가지로, 실 거래시에는 나타나지 않았지만 백테스팅할 때만 나타나는 문제점이 있다는 반대의 경우도 존재한다. 바로 대표적인 경우가 일봉 차트를 기반으로 거래를 진행할 때에 나타나는 문제점이다. 만약 주가가 어느 하루 동안 높은 변동성을 가진 일봉을 형성했다고 가정했을 때, 실 거래 시에는 실시간 가격적 변동에 의해 거래를 진행하기 때문에 문제가 없지만 백테스팅 시에는 문제가 발생할 수 있다.(분봉 차트가 무한정 제공되지 않기 때문이다.) 아래의 도식을 살펴보도록 하자.

위의 도식 중 가운데를 가로지르는 검정색 선이 예정 매수 가격이라고 가정하고, 가장 맨 오른쪽에 위치해 있는 도지봉을 살펴보도록 하자. 주식을 했던 사람이라면 오른쪽 도지봉이 어떠한 주가 형태였을 경우에 나타나는 봉의 모습인지 어렵지 않게 상상해볼 수 있다. 도지봉의 주가 흐름만 자세하게 한 번 살펴보도록 하자.
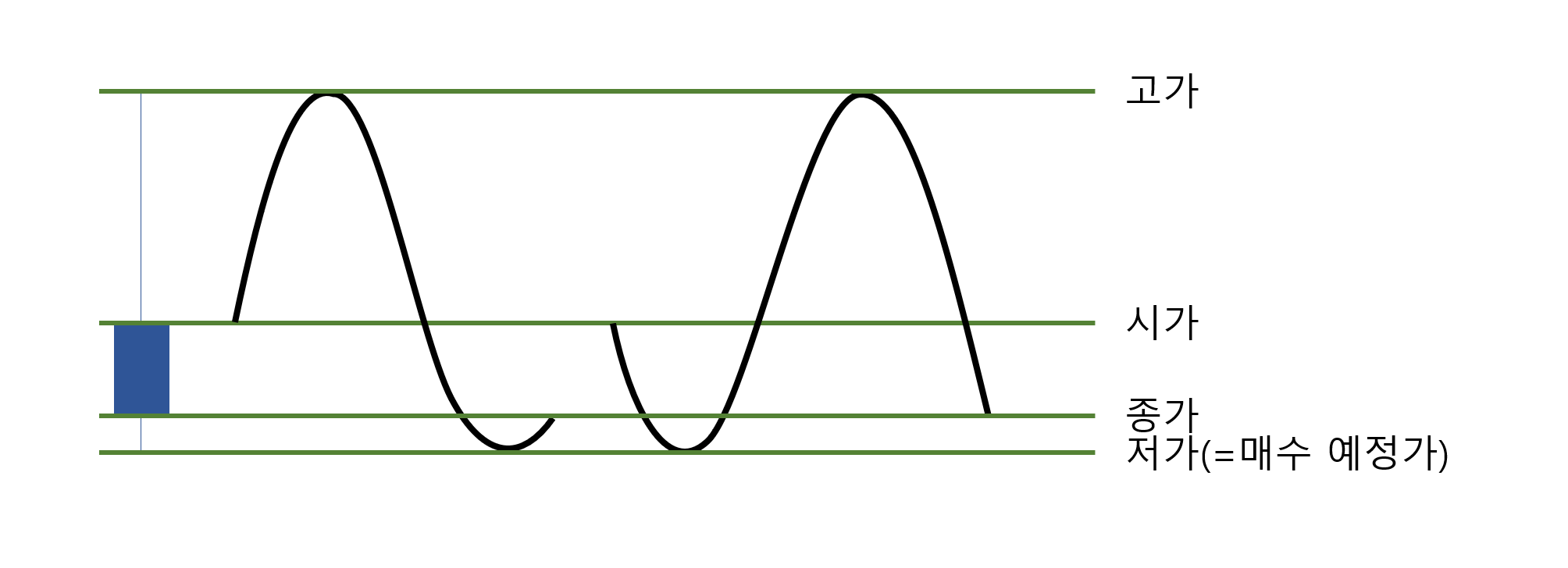
위의 도식을 살펴봤을 때, 저가가 매수예정가라고 했을 때 왼쪽의 주가 흐름은 이미 어느 정도의 반등이 등장한 후에 매수 예정가에 도달했고 오른쪽의 주가 흐름은 매수 예정가에 도달한 이후에 반등이 등장했다. 실 거래 상에서는 이 두 가지 흐름이 구분이 가능하다. 백테스트 과정에서 기간 상의 문제로 분봉 데이터가 아닌 일봉 데이터를 대상으로 백테스트를 진행하게 된다면 위와 같은 흐름을 구분해낼 수 없게 된다.
또, 아래와 같이 고가가 매도 예정가였다고 가정해보도록 하자.
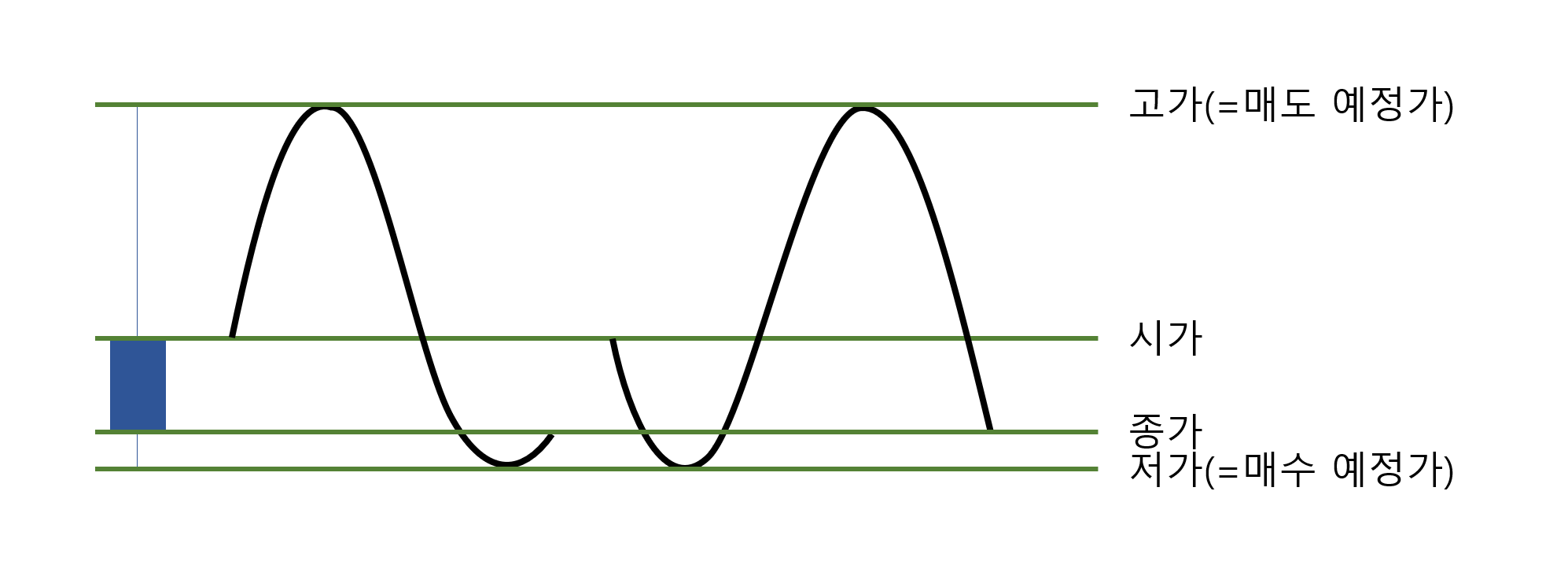
백테스트 과정에서, 백테스트 알고리즘은 위의 흐름에 대해 다음과 같은 판단을 내릴 것이다. 저가는 매수 예정가에 닿았으니 매수를 진행하고, 고가는 매도 예정가에 닿았으니 매도를 진행하게 된다. 즉, 당일에 매수한 후에 당일에 매도한다는 것이다. 다시 말해, 실제 주가의 흐름이 오른쪽과 같았다면 문제가 없었겠지만 왼쪽의 흐름이었다면 실제로는 매수도 매도도 이루어지지 못하는 주가 흐름이었기 때문에, 백테스트 코드는 정상적으로 동작하지 않는다는 것이다.
물론 이런 부분들에 대해서는 분봉 상 데이터를 기반으로 진행하는 것이 깔끔하겠지만, (키움증권의 경우) 분봉 데이터를 제한적으로 제공하고 있기 때문에 데이터가 없는 경우도 있기 때문에 일봉 차트를 기반으로 백테스트를 한다면 위와 같은 부분을 염두에 두어야 한다.
백테스팅 시에 사용하는 알고리즘이 올바르게 동작하는지 확인해야 한다.
알고리즘을 제작할 때에는 한 가지 종목을 대상으로만 제작해놓고 정상적으로 동작한다고 생각되어 막상 백테스팅을 해보면 그 종목에 한해서만 정상적으로 동작할 가능성이 농후하다. 여러 가지 유형의 종목들에 대해서도 알고리즘을 적용해보고, 본인이 원하는 그리고 의도했던 대로 거래 데이터가 계산되어 나오는지를 확인해주어야 한다. 간혹 어떤 종목에 대해서는 정상적으로 동작하나 그 외 몇 가지 종목에 대해서는 오류를 남발하거나 오류가 없더라도 정상적으로 동작하지 않을 가능성이 있다.
실제로도 코딩을 조금만 해봤으면 당연히 알 만한 내용 중 하나인데, KeyError나 TypeError 등과 같은 문법 또는 구조적 오류는 발생하지 않았으나 실제 결과 데이터를 살펴보니 오류가 있는 경우들이 있다. 이런 경우에는 원인이 어느 지점인지를 모르기 때문에 문제를 해결하기가 굉장히 까다로워진다.
바로 앞서 살펴봤던 "하루에 매수 에정가와 매도 예정가 모두에 닿아 매수가 가능했는지 불가능했는지를 판단하기 어려운 경우" 외에도 다양한 요인들이 존재한다. 예를 들어 손절가가 그때 그때 변경되어야 하는데 그 부분을 빼먹는 바람에 손절폭을 어떻게 설정해도 큰 수익이 발생한다던지 하는 것들 말이다. 즉, 알고리즘을 생성했고 백테스팅을 돌렸다면 백테스팅 결과로 얻은 데이터를 실제 차트와 대조해보며 알고리즘과 백테스팅이 정상적으로 동작했는지를 크로스체크해야 한다. 사실 이런 작업은 반드시 이루어져야 하는 이유는 바로 "본인이 갖고 있는 돈"을 투입하는 것이기 때문이다. 내 돈을 내가 코드를 엉뚱하게 짜서 매번 손실만 보는 알고리즘에 들어갔다면 얼마나 분하겠는가?(그래서 알고리즘 테스트는 반드시 모의투자로 진행해야 한다.)
필요한 데이터를 모두 입력하고 확인하라.
이 내용은 앞서 다루었던 백테스팅의 의의와도 일맥상통하는 내용에 해당하기도 하는데, 통상적으로는 백테스팅 결과 데이터를 기반으로 어떤 데이터를 얻길 원하는지를 생각하고, 그 데이터를 직접 만들어주어야 한다. 하지만 실질적으로 백테스트을 시작하는 입장에서는 백테스트를 통해 어떤 데이터들을 얻어와야 하는지에 대해 무지하므로 일종의 가이드라인이 되었으면 하는 마음에 작성하게 되었다.
물론 이는 본인의 알고리즘이 어떠한 거래 방식을 지향하는지에 따라 각각 다르게 작용하겠지만, 통상적으로 백테스팅을 통해 살펴보고자 하는 내용은 다음 두 가지 리스트에서 크게 벗어나지 않을 것이다.
- 손절폭(거래 단위 별로 얼만큼의 손절폭을 감내해야 확률이 좋은가?)
- 수익률(거래 단위 별로 얼만큼의 수익률을 기대해볼 수 있는가?)
하지만 이 두 가지 범주는 결과적으로는 "승률"이라는 범주에 들어가는 내용이기도 하다. 승률이란 예상외로 다양한 개념들을 내포하고 있는 개념이라 생각되는데, 예를 들어 손절폭을 길게 잡고 수익률을 낮게 잡을수록 승률은 올라간다. 왜냐하면 약간의 수익을 얻기 위해 깊은 손절폭을 감내하는데(하이리스크 로우리턴) 승률이 낮을 수가 없다. 반대로 손절폭은 짧게 잡고 수익률을 길게 잡을수록 승률은 하락한다. 이 역시 로우리스크 하이리턴이기 때문에 승률이 높을 수가 없다.
다만 어느 정도의 손절폭을 설정하고 어느 정도의 수익률을 기대하는 것이 합당한가에 대해 살펴보는 것이 백테스팅의 의의이다. 따라서 백테스트를 진행할 때에는 "수익 매도 이후 주가가 어느 지점까지 상승했는지"나 "어느 지점까지 하락한 후에 상승세를 보였는지" 등과 같은 데이터가 포함되어 있어야만 백테스팅 결과물로서의 의의를 갖고 알고리즘을 수정하는 데에 유용한 기반이 되어줄 수 있다. 즉, 본인이 기존에 설정한 알고리즘 내에서만 거래를 진행한다고 할 때, 최소한의 손실로 최대한의 수익을 얻는 적당한 지점을 찾는 과정이 바로 백테스트인 것이다. 아래의 실제 예시를 기반으로 백테스트를 통해 어떤 부분들을 수정해야 하는지 살펴보도록 하자.
본인이 얼마 전 새롭게 만든 알고리즘 4번 수익 모델이 있는데, 해당 모델은 사전에 계산된 매수가 가격을 근본적 전제로 두고(변하지 않음), 그 외의 변수로 하여금 거래 방식을 조금 다르게 진행한다. 그 중 대표적인 것이 바로 10일 이동평균선을 이탈했을 때에만 매수하도록 하며, 사전에 계산된 예정 매수 가격으로부터 2%의 손절폭을 갖도록 하고 있었다. 이때 본인이 설정한 알고리즘이 갖는 변수의 유용성과 실효성을 높이기 위해선 ①10일 이동평균선을 이탈한 후에 매수하는 전략의 유효성과 ②손절폭을 2%로 제한하는 것으로 충분한지를 살펴보고 알고리즘을 수정하는 것이다. 백테스트 결과는 아래와 같다.
[10일 이동평균선 이탈 여부]
- 전체 47건 거래 중 10일 이동평균선 이탈 거래는 7건, 나머지 40건은 10일 이동평균선 위에서 거래가 이루어짐
- 이탈 거래인 7건 중 손실 거래는 2건, 미이탈 거래인 40건 중 손실 거래는 3건
- 10일 이동평균선을 기준으로 매수 여부를 판단하는 것은 유효하지 않음 → 알고리즘 전략 수정
- 오히려 10일 이동평균선을 이탈하지 않았을 때 매수하는 것이 더 성공률이 높은 것으로 판단
[2%의 손절폭은 충분한가]
| 구분 | 2% | 4% | 5% | 10% |
| 손실 비율 | 19.15%(9건/47건) | 14.8%(7건/47건) | 10.63%(5건/47건) | 6.25%(3건/48건) |
| 수익 금액 | 6,856,246원 | 7,316,481원 | 8,275,947원 | 8,665,252원 |
- 매수 이후에 형성된 최저점의 위치를 기반으로 알고리즘이 감당해야 하는 손절폭을 결정하는 것
- 2%는 손실 거래가 다른 경우들에 비해 잦고, 4%로 늘렸음에도 거래 성공률이 90%가 채 되지 못함
- 5%와 10%간 손실 거래의 비율을 비교해보면 10%로 설정했을 경우 손실 비율이 급격하게 감소하며, 수익금액도 더 커짐
- 하지만, 5%로 결정(지수의 급락 또는 투매 등으로 인한 리스크를 관리하기 위해선 10%의 손실폭은 너무 큼)
백테스트 결과를 위와 같은 방법들을 통해, 기존에 ①10일 이동평균선 이탈 시에만 매수하고 ②2%의 손절폭을 갖도록 설정했던 알고리즘을 ①10일 이동평균선의 이탈 여부와 무관하게 매수하고 ②5%의 손절폭을 갖도록 하는 알고리즘으로 수정할 수 있다. 이처럼 백테스트를 기반으로 생성된 자료를 활용하여 알고리즘의 로직을 변경함으로써 거래의 수익을 극대화할 수 있다.
백테스트 결과를 알고리즘에 녹여내는 여러 가지 방법들 중, 개인적으로 가장 추천하는 방법은 데이터를 엑셀로 저장하여 데이터들을 시각화함으로써 알고리즘에 보다 효과적으로 녹여내는 것이다.(데이터의 시각화에 일가견이 있으신 분이라면 그 방법대로 하는 게 가장 좋은 방법일 수도 있다.) 아래의 점차트는 본인이 "손절폭" 설정값을 변경할 때 만들었던 데이터인데, 이를 바탕으로 분석해보도록 하자.

본인의 알고리즘 4번 수익 모델은 두 가지 지점에 걸쳐 분할 매수를 진행하고 있다. 당연히 손절폭을 수정하기 위해 제작한 자료이니 만큼, 매수 시점 이후에 매수 지점 대비 얼만큼의 하락을 보여주었는지를 살펴보는 것이다. 다시 말해, 매수 예정 가격이 100원일 때 매수 이후 주가가 100원까지 하락했다면(즉, 매수한 즉시 상승했다면) 둘 간의 비율은 0%로 나오게 된다. 하지만 100원일 때 매수했으나 주가가 90원까지 하락한 후에 상승했다면 그 비율은 -10%로 나오게 되며, 이 수치가 4번 알고리즘이 감당해야 하는 손절폭에 해당하는 것이다.
본인의 경우 분할 매수를 진행하고 있기 때문에, 첫 매수 지점으로부터 얼만큼 하락했는가는 중요하지 않다. 어차피 하락하면 추가적으로 매수할 것이기 때문이다. 따라서, 오른쪽 사진을 자세히 살펴보도록 하자. 오른쪽 사진은 두 번째 매수 가격을 기준으로 주가가 어디까지 하락했는가를 나타내는 점차트이다. 빨간색 동그라미가 쳐져 있는 0.00%를 기준으로 위에 있는 점들은 두 번째 매수가 이루어지지 않았다는 것이다. 다시 말해, 첫 번째 매수만 이루어졌고 두 번째 매수는 이루어지지 않은 채 상승했다는 의미이다.
그렇다면 0.00% 밑에 있는 점을 중심으로 수정해야 하는데, -2% 지점까지 총 3개의 점이 있고 그 이후부터는 -5%~6% 지점까지 하락하는 경우들이 많이 존재하고,그 밑으로는 -8%까지도 하락한다는 사실을 확인할 수 있다. 이제 이 내용을 바탕으로 손절폭을 결정해주면 된다. 즉 ①깔끔하게 -2%까지의 손절만 감당하고 지나갈 것인지, 아니면 ②-5%~-6% 지점까지도 고려할 것인지, 아니면 ③-5%~-6% 지점이 -2%~-3% 지점이 되도록 두 번째 매수 지점을 조금 더 낮출 것인지(물론 이 경우, 매수 가격이 낮아짐에 따라 기존에는 매수했던 종목들을 매수하지 못하는 일이 발생할 수 있다.) 등과 같은 전략으로 수정하는 것이다.
728x90
반응형
Contents
소중한 공감 감사합니다